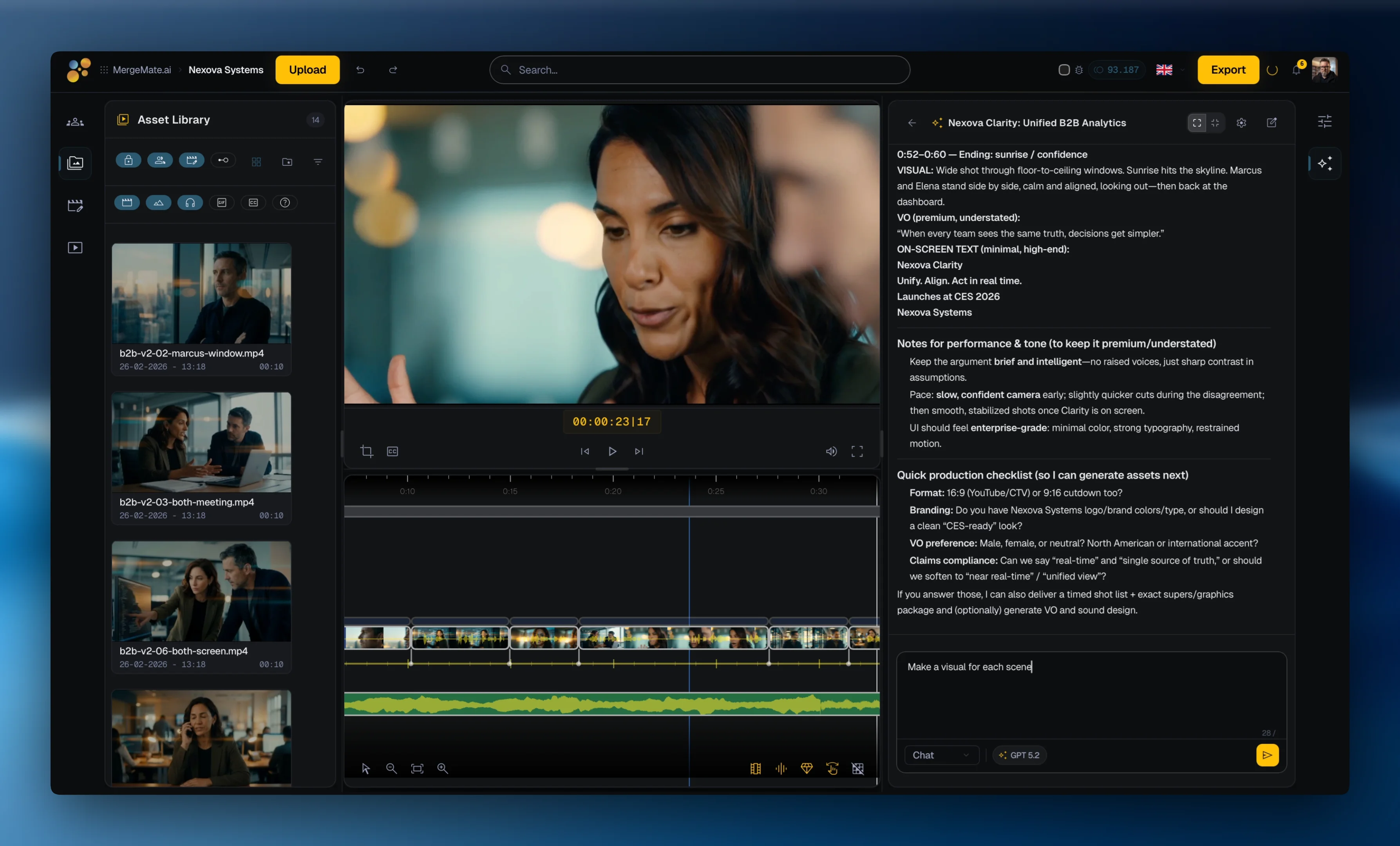
35+ Active AI Models, One Platform
MergeMate.ai integrates 35+ active AI models and capabilities for video, image, audio, music, text, and upscaling. Your AI agent picks the right model for each task — you just choose the best result.
How MergeMate.ai routes models by production task
| Production task | Model category | Example integrations | Output in workflow |
|---|---|---|---|
| Text-to-video | Video generation | Runway, Google Veo, Seedance | Generated shots tied to the project |
| Image-to-video | Video generation | Runway, Google Veo, Kling | Animated reference frames and storyboard clips |
| Storyboard images | Image generation | FLUX, Imagen, GPT Image | Visual references for scenes and moodboards |
| Voiceover/dialogue | Voice and audio | ElevenLabs | Narration or dialogue drafts for review |
| Sound/music | Audio and music | ElevenLabs, Lyria, MiniMax | Scene audio, sound effects, or music options |
| Upscaling | Enhancement | real-esrgan | Improved generated or uploaded visuals |
| Transcription/subtitles | Speech and text | Transcript and subtitle workflows | Searchable text, captions, and localization context |
| Analysis/text planning | Reasoning and text | GPT, Gemini, DeepSeek | Brief analysis, scripting, planning, and review summaries |
Why multi-model video production matters
No single AI model is best at every job. Teams need orchestration, asset context, review, and delivery so each model output can become useful production material instead of another disconnected file.
Model choice without workflow chaos
Mergi helps keep prompts, model outputs, references, comments, and next steps in the same project context, so teams can compare model strengths without losing the production thread.
One Chat, Every Model
Unlike tools that lock you into a single AI provider, MergeMate.ai uses a unified schema across all models. Ask your AI agent to generate a video clip — it routes to RunwayML, Seedance 2.0, Kling, Runway, Veo, FLUX, Imagen, GPT, Gemini, DeepSeek, ElevenLabs, or Lyria based on your requirements. Same prompt, best model, best result.
New models are integrated continuously. As the GenAI landscape evolves, your editing platform evolves with it — no migration, no switching tools.
Video Generation
10+ models & capabilities
DreamActor M2.0
Active ByteDance video generation model for character and performance-driven clips
ByteDance →Kling Video 3.0
Active Kling video generation model for cinematic text-to-video and image-to-video workflows
Kuaishou →Kling Video 3.0 Omni
Active Kling variant for broader multimodal video generation workflows
Kuaishou →And many more…
Image Generation
12+ models & capabilities
FLUX.2 [max]
Active Black Forest Labs image model for high-quality concept and production visuals
Black Forest Labs →FLUX.2 klein 4B
Active lightweight FLUX.2 model for fast image generation iterations
Black Forest Labs →Nano Banana
Active Google image model for creative asset generation
GoogleNano Banana 2
Active Google image model for production-ready visual options
GoogleNano Banana Pro
Active Google image model for premium image generation workflows
Googlereal-esrgan
Active image upscaling model for improving generated and uploaded visuals
NightmareAI integration →And many more…
Audio & Voice
6+ models & capabilities
ElevenLabs Sound Effects
Active sound-effect generation for cinematic and social video workflows
ElevenLabs →ElevenLabs Voice
Active text-to-dialogue voice generation for narration and dialogue workflows
ElevenLabs →Lyria 3
Active Google music generation model for soundtrack exploration
GoogleLyria 3 Pro
Active Google music generation model for advanced soundtrack workflows
GoogleMiniMax Music 2.6
Active MiniMax music generation model for production audio options
MiniMaxAnd many more…
Text & Analysis
8+ models & capabilities
DeepSeek V4 Flash
Active fast reasoning model for production assistance and lightweight text generation
DeepSeekDeepSeek V4 Pro
Active reasoning model for deeper production planning and text workflows
DeepSeekGemini 3.1 Pro
Active Google model for advanced project analysis, planning, and creative direction
Google →And many more…
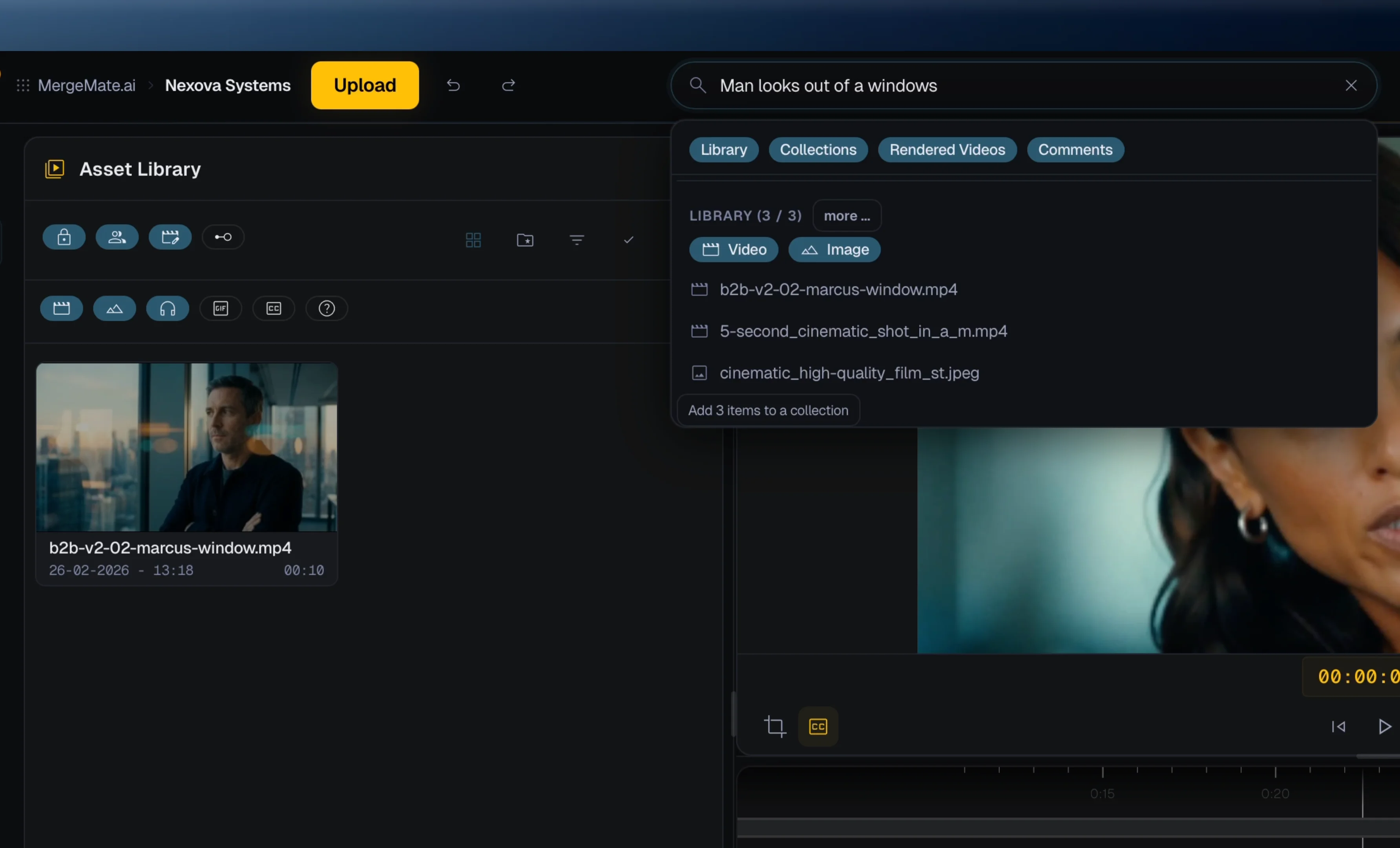
AI-Powered Media Analysis
Beyond generation, MergeMate.ai uses AI models to deeply analyze your footage — objects, scenes, colors, emotions, speech. Every asset is tagged with AI assistance and indexed in a vector database for instant semantic search.
- Automatic content tagging and metadata extraction
- Vector similarity search across all assets
- Visual embeddings for find-by-example queries
- Scene and emotion detection in footage
AI models FAQ
What AI models does MergeMate.ai support?
MergeMate.ai positions 35+ active AI models and capabilities across video, image, audio, voice, music, text, and upscaling workflows.
Why use multiple AI video models?
No single model is best at every production task. Teams need different strengths for text-to-video, image-to-video, voice, sound, images, analysis, upscaling, and delivery support.
Can MergeMate.ai route different tasks to different models?
Yes. Mergi is positioned as the project-aware layer that can help route production tasks to suitable models and keep outputs connected to the workflow.
Does MergeMate.ai replace standalone AI model tools?
MergeMate.ai is not framed as a replacement for every standalone tool. It gives teams a production surface where model outputs, assets, prompts, review, and delivery stay connected.
How do AI models connect to project memory?
Project memory keeps prompts, generated outputs, source assets, comments, and decisions connected so model results remain usable in later revisions.
See MergeMate.ai in Action
MergeMate.ai is built by founders combining 25+ years of professional film production with software architecture for AI orchestration, collaboration, and cloud workflows.
By Thomas Fenkart — 25+ years in professional video production · Last updated: March 2026
Get in early.
Shape what it becomes.
MergeMate is in Early Access. We're not looking for beta testers — we're looking for co-builders. Get in now, shape what it becomes, and pay a lot less than everyone who waits.